[C] 纯文本查看 复制代码 // TCM内存分配
static uint32_t tcm_buffer[MEM_SIZE];
// SRAM内存分配
static uint32_t __attribute__((section(".RAM_D1"))) sram_buffer[MEM_SIZE];
// 读测试
void bench_mem_read(const char* name, uint32_t* mem, size_t size) {
volatile uint32_t temp;
for(size_t i = 0; i < size; i++) {
int s = DWT->CYCCNT;
temp = mem[i];
int e = DWT->CYCCNT;
rt_kprintf("read time: %d\n", e - s);
}
}
// 写测试
void bench_mem_write(const char* name, uint32_t* mem, size_t size) {
for(size_t i = 0; i < size; i++) {
int s = DWT->CYCCNT;
mem[i] = (uint32_t)i;
int e = DWT->CYCCNT;
rt_kprintf("write time: %d\n", e - s);
}
}
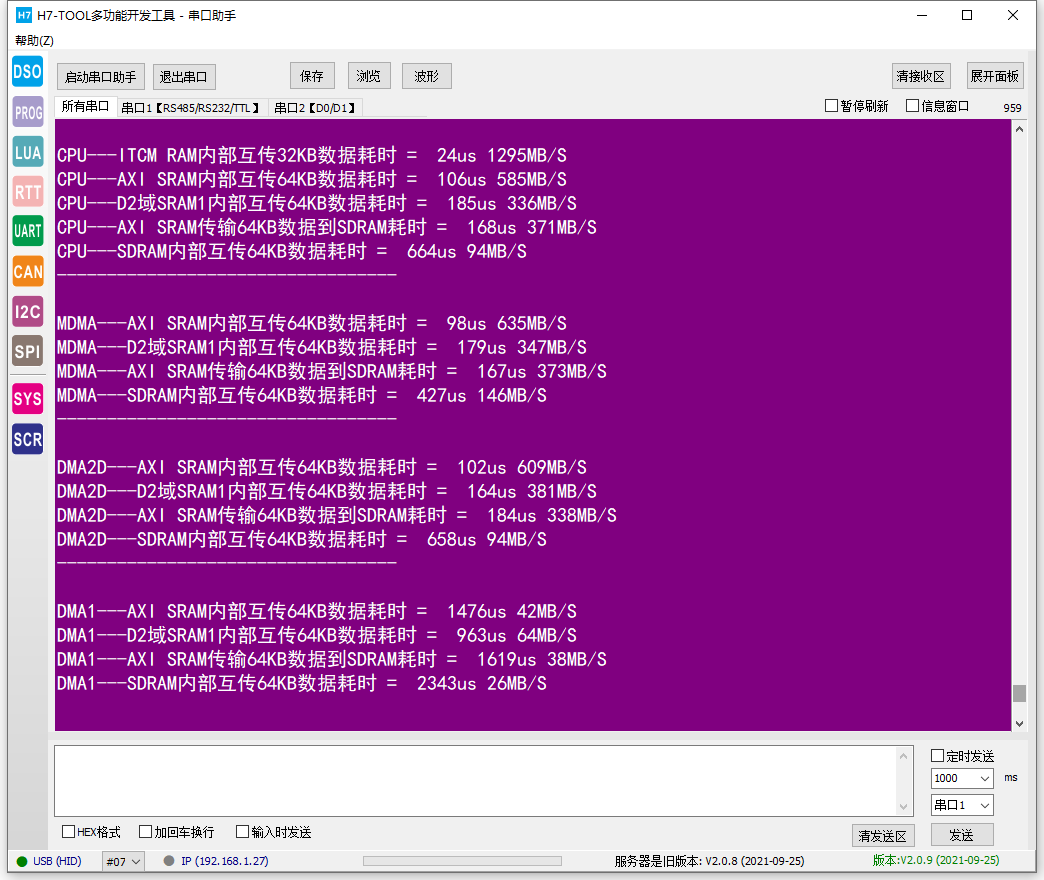
我的大致测试思路是启用DTCM为主内存,手动分配SRAM内存,然后通过这两个核心函数测试取值赋值的计数,前面两者基本上没啥差距(Cache全部Disable了,SRAM的MPU也设置成了NOTCACHEABLE,总体来说DTCM的情况稍好一点),后面我试着调高了代码编译的优化等级,同时勾选了时间优化的选项,结果倒是比较正常了
开启代码优化前:
 
开启代码优化后:
 
我总结下我的问题,烦请硬汉哥指教一下:
1. 是不是我的测试代码走了弯路导致大部分时间花在了其他地方而不是内存访问(结合优化等级的影响我觉得比较合理)?
2. 实验过程中发现DTCM的访问时间确定性确实很稳定,200轮测试访问CPU周期都是409个周期(第一次访问431周期原因未知,也是我疑惑的地方),而SRAM会不定时出现访问周期骤变的情况,针对这两个现象我怀疑和DTCM或SRAM内部的内存分区有关(Bank、Chunk之类),想请问下硬汉哥该怎么解释?
3. 看手册了解到DTCM的数据总线是和CPU同频的,理论上是不是一个CPU周期就能够读取64bit数据(TCM总线位宽为64)?我也看了硬汉哥的例程手册,上面有提过实际上RAM达不到400MHz,我的测试速度慢是不是和这个也有关系? | 


 发表于 2024-7-25 10:06:20
发表于 2024-7-25 10:06:20






 发表于 2024-7-25 11:31:26
发表于 2024-7-25 11:31:26
 楼主
楼主




{kind=link}
{kind=link}